
大抵又是挖了个大大大的坑
不过还是想坚持下来
png 结构
一切都从 0 开始,先说明下常见的 png 图片的结构
png 文件签名 (Signature)
png 文件以固定的 8 字节签名开头,用于标识文件类型:
1 | 89 50 4E 47 0D 0A 1A 0A |
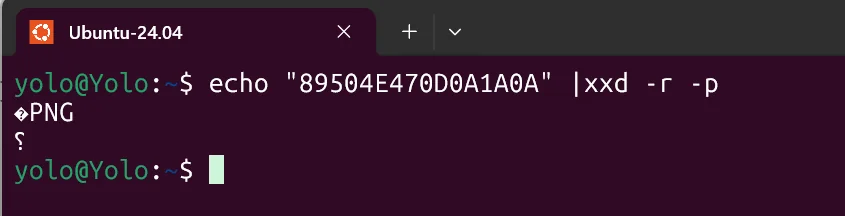
emm,见多 png 图片结构的话,就很快发现这是 png 的文件头了,然后进行后续操作,比方说 zip 的明文攻击等等
数据块 (Chunks)
png 文件由多个数据块组成,每个数据块包含特定类型的信息。数据块是 png 的核心结构,可以被分作这几个部分
-
长度(Length):4 字节,指定数据段的字节数(不包括长度、类型和 CRC)。
-
块类型(Chunk Type): 4 字节 ASCII 码,标识数据块的功能(如
IHDR、IDAT等) -
数据 (Chunk Data): 长度指定的数据内容,可能是图像元数据、像素数据等。
-
CRC 校验(CRC):4 字节,循环冗余校验码,确保数据块完整性。(请注意,crc 计算范围只有块类型和数据,其他两个部分不要算入)
数据块分为关键块(必须有)和辅助块(可选)。常见数据块如下:
关键块
IHDR(文件头数据块)
是数据块的起点,每个正常的 png 图片有且只有一个 IHDR 块。它会定义图像的基本信息:
-
宽度(4 字节)
-
高度(4 字节)
-
位深度(1 字节,如 1、2、4、8、16)
-
颜色类型(1 字节,定义颜色模式:0=灰度,2=RGB,3=索引颜色,4=灰度+Alpha,6=RGB+Alpha)
-
压缩方法(1 字节,通常为 0,表示 deflate)
-
滤波方法(1 字节,通常为 0)
-
隔行扫描方法(1 字节,0=非隔行,1=Adam7 隔行)
tips:总感觉这里有出题的新点,通过渲染不同行的类型,让一张照片有不同的样子
这里可以总结下
IHDR 数据块的固定长度:IHDR 的数据段总是 13 字节(宽度 4+高度 4+位深度 1+颜色类型 1+压缩方式 1+滤波方式+隔行扫描方法 1)
字节序:所有多字节字段(如宽度、高度)使用大端序
做个小解释
这里相信有小白没看懂吧,哈哈,其实我也有点点疑惑了,发现不太好理解,这里我举个例子
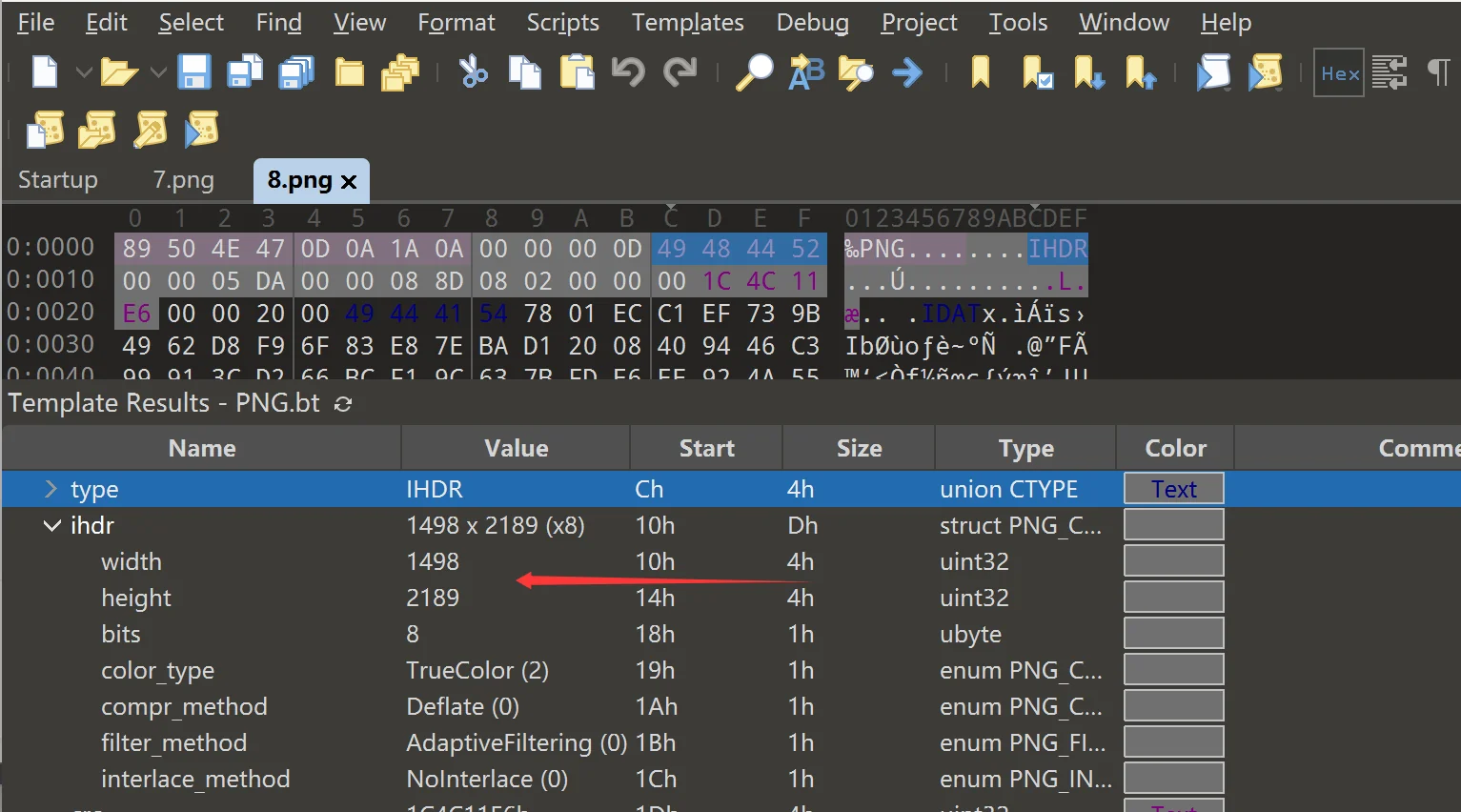
1 | 89 50 4E 47 0D 0A 1A 0A 00 00 00 0D 49 48 44 52 00 00 05 DA 00 00 08 8D 08 02 00 00 00 1C 4C 11 E6 |
这里先看前 8 个字节,就是我前面说的 png 文件签名,然后按照顺序就来到了数据块,我说过,数据块应该被分作 4 各部分,其中是长度 4+块类型 4+数据(字节数不一定,得看块的类型,但是字节大小一定和前面长度一致)+CRC 校验 4
那这就很好看了,去掉文件签名后,剩下这些00 00 00 0D 49 48 44 52 00 00 05 DA 00 00 08 8D 08 02 00 00 00 1C 4C 11 E6先看 4 字节的长度 00 00 00 0D 我前面说过,这里是用大端序存储的,把 16 进制转换成 10 进制,就是 13,哈哈,猜到这是什么数据块了吧,没错就是 IHDR,这一点你可以将那个 49 48 44 52 进行 ASCII 解码就能看到,然后是数据段,00 00 05 DA 转换 10 进制就是 1498 像素,然后 00 00 08 8D 转换后是 2189 像素,位深度是 08,意味着 8 位,这是个常见值,然后颜色类型 02 表示的是 RGB 模式,压缩方式 00 表示的是 deflate 压缩,滤波方式 00 表示标准自适应滤波,隔行扫描方法 00 表示非隔行扫描(逐行渲染)。分析完数据块后,来到了 CRC 校验,1C 4C 11 E6,这个可以校验 IHDR 类型和数据段的计算结果是否匹配,大致理解成 md5 校验还是可以的吧,上面的内容,我们可以用 010 查看,这样的话就能很直观的分析,处理数据了
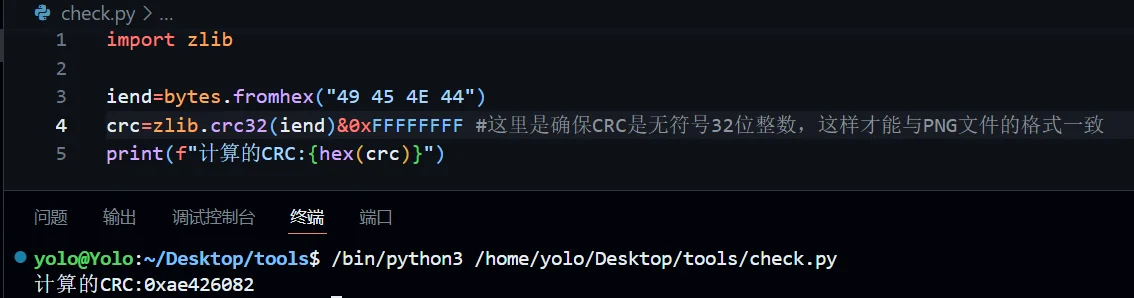
这里我们可以计算下 CRC,验证下
1 | import zlib |
校验成功,好了,上述内容是单独对一个块的分析处理,其他的块大同小异,我后面就会稍微简略的带过了
IDAT(图像数据块)
通常会在辅助块 PLTE(如果有的话)之后,而且一张 png 照片中可能会有多个 idat 块,它们会解码时按照顺序进行拼接
里面的内容是压缩后的图像像素数据,使用的是 deflate 算法,作用则是存储实际的图像数据(也就是说图片里的内容和这个 idat 块有关
做做了解好了
这里需要探讨下 idat 块的大小限制,通过脚本,可以实现任意大小的 idat 块的实现,通过 ai 的解释,目前常见的 idat 块最大是 65536 字节,它是由于 zlib 的默认缓冲区通常是 64KB 而限制的,当字节数达到 65536 的时候,为了适应缓冲区,我们就直接打包成一个 idat 块,然而对于不同的平台,或编译器,甚至人为,能产生不同版本的 idat 块。这是因为 idat 块只有唯一种压缩算法(deflate),最后出现在显示屏上的是所有 idat 块按照顺序拼接得到的结果,这也就可以解释为什么有的 idat 块明明没有达到自身最大的 idat 块的时候直接打包,进入下一个 idat 块的编写的时候,文件依然可以正常打开查看
这里打包有个特点,就和我前面说的 png 数据块的结构那样长度 4+块类型 4+数据块(大小不一定,但与长度的值一致)+CRC4
而这也就意味着,只要所有的 idat 块满足这个结构就算合法,并没有所谓的大小限制(理论上大小其实由 length 决定,因为它只有 4 个字节,最大也就只能达到 2^31-1 字节,也就是 2GB 的大小,不然的话,我们的 png 结构会报错的
这里有个脚本,允许我们生成自定义 idat 块大小的 png 图片
1 | import png # 需要安装 pypng: pip install pypng |
这里稍微普及下 DEFLATE 算法,这个知识点在 zip 压缩中也会被用到,它结合了 Huffman 编码和 LZ77 算法,通过这两个主要步骤实现高效压缩:
-
LZ77 算法:用于查找和替换重复的数据序列(字符串),以减少冗余。
-
Huffman 编码:对数据中的符号(字节或匹配标记)进行变长编码,常见符号分配较短的编码,稀有符号分配较长的编码,从而进一步压缩数据
在将图像数据传递给 DEFLATE 算法之前,PNG 会对每一行像素数据应用过滤器。过滤的目的是减少相邻像素之间的数值差异,使数据更适合压缩。png 定义了 5 种过滤类型(0 到 4):
-
类型 0:无过滤:直接使用原始像素值。
-
类型 1:Sub:当前像数值减去前一个像素值
-
类型 2:Up:当前像素值减去上一行对应位置的像素值。
-
类型 3:Average:当前像素值减去前一个像素和上一行像素的平均值。
-
类型 4:Paeth:使用 Paeth 预测器,基于前一个像素、上一行像素和左上角像素进行预测
这里进行预处理的原因是过滤后的数据通常具有较小一点的变化波动以及更多的重复模式,这使得后面的 DEFLATE 压缩能更加高效。(tips:每行数据的第一个字节会记录使用的过滤器类型,解码时会根据此信息还原原始像素值)
具体的 deflate 压缩步骤还是有点复杂,涉及 lz77 算法和 huffman 树,暂时没有研究透,我后面会在 zip 专栏中记录它们的原理
IEND(文件尾数据块)
这是关键块的最后一部分
1 | 00 00 00 00 49 45 4E 44 AE 42 60 82 |
就和 png 文件签名那样,这里的文件尾数据块也是特定的,细剖下,00 00 00 00 代表着数据块的内容为空,49 45 4E 44 转换成 ASCII 后就是 IEND,接下来直接到 CRC 校验部分 AE 42 60 82
辅助块
这里的辅助块有点小多,而且涉及到的考点,目前我是没有接触过,所以我选择快速说明种类和功能
PLTE(Palatte)
-
作用:定义调色板(索引颜色模式)的颜色表
-
内容:每三字节表示一个颜色(RGB),最多 256 个颜色(768 字节)
-
出现位置:在 IDAT 块之前。
-
必须性:仅当颜色类型为 3(调色板模式)时必须存在;对于其他颜色类型(如 RGB、灰度)是可选的或禁止的
TIP
调色板模式就是我在 IHDR 中写到的类型 3:索引模式
还有其他 13 个真·辅助块
-
图像显示:tRNS,bKGD,sRGB,pHYs
-
颜色管理:cHRM,gAMA,iCCP,sRGB,sBIT
-
元数据:tEXt,zTXt,iTXt,tIME
-
调色板优化:hIST,sPLT
我这里不打算一一列举,给推荐两个官方文章,上面有相关介绍
Portable Network Graphics (PNG) Specification (Third Edition)
上面的是官方给出的说明,可能理解上有点点困难
这是libpng提供的手册,可能会更好理解一点
summary
数据块结构
graph LR
A[Length
4字节] --> B[块类型
4字节]
B --> C[内容
Length字节]
C --> D[CRC校验
4字节]
基本的 png 结构
graph TD
A[PNG签名
8字节] --> B[IHDR块
关键块
Length: 13字节
Type: IHDR]
B --> C[PLTE块
可选块
Length: 可变
Type: PLTE
仅用于调色板模式]
C --> D[IDAT块
关键块
Length: 可变
Type: IDAT
可能多个]
D --> E[IEND块
关键块
Length: 0字节
Type: IEND]
png 攻击汇总(其实偏隐写了
这里呢,我会记录一些 ctf 中常见的 png 考点,会断断续续进行更新
png 攻击真的好多,很丰富,这里我会针对 png 格式特有的攻击技巧进行记录整理
文件插入字符信息
这里玩的也挺花,首先一种是直接暴力添加,将一串字符,甚至 flag 直接拼接到 png 图片的 IEND 块后面,这是被允许的,因为编译器在识别 png 图片的时候,会严格从 PNG 文件签名开始,然后到 IEND 块结束,后面的字符串,它们不会理会,也就不会报错了,这也算是送分题或放 hint 了
其他的方法就是利用 png 辅助块隐藏信息,常见的可以隐藏文本的辅助块如下:
-
tEXt 块:存储未压缩的文本数据,通常用于元信息(如作者、描述)。数据内容的格式是
[关键字]\0[文本内容] -
zTXt 块:存储压缩的文本数据(使用 zlib 压缩) 数据内容的格式:
[关键字]\0[压缩标志]\0[压缩数据],压缩标志通常为 0 -
iTXt 块:支持国际化文本(UTF-8 编码),可以存储压缩或未压缩数据。 数据内容的格式:
[关键字]\0[压缩标志]\0[压缩方式]\0[语言标签]\0[翻译关键字]\0[文本] -
最后还有种自定义辅助块,首先满足基本块的结构,里面存放数据即可,(块类型为小写字母开头)解析器会忽略不认识的块
能考查到的这一部分知识点就这些了吧
推荐几个工具,首先是 010 editor,最厉害的十六进制编辑器,通过这个可以直接用‘瞪眼’法(大佬一定可以,我还不行
然后推荐使用 TweakPNG 工具,它可以帮助我们将图片里的所有数据块整理出来,后续在其他攻击中还能用它直接敲除或提取多余,特殊的 IDAT 块
接下来再推荐个工具 exiftool,它可以帮我们快速将 png 的元信息提取出来
这里 yolo 想学习自己写个妙妙工具,就在这里立个 flag 吧,后期我会把仓库链接补充到文章下面的
在对 py 的认真学习,以及在 ai 的帮助下,终于完成这个小脚本
1 | import struct |
使用方法是 python3 png_extract.py -f xxx.png
这里给分享个我用来生成测试 png 的脚本
1 | import struct |
各位大佬简单看看我的脚本就清楚怎么使用了吧,这是我随便弄的一个测试例子
python3 createpng.py -o image_with_texts.png -W 300 -H 200 -t tEXt Author "Bob" -t zTXt Comment "This is a test image" -t iTXt
结构缺失、混乱
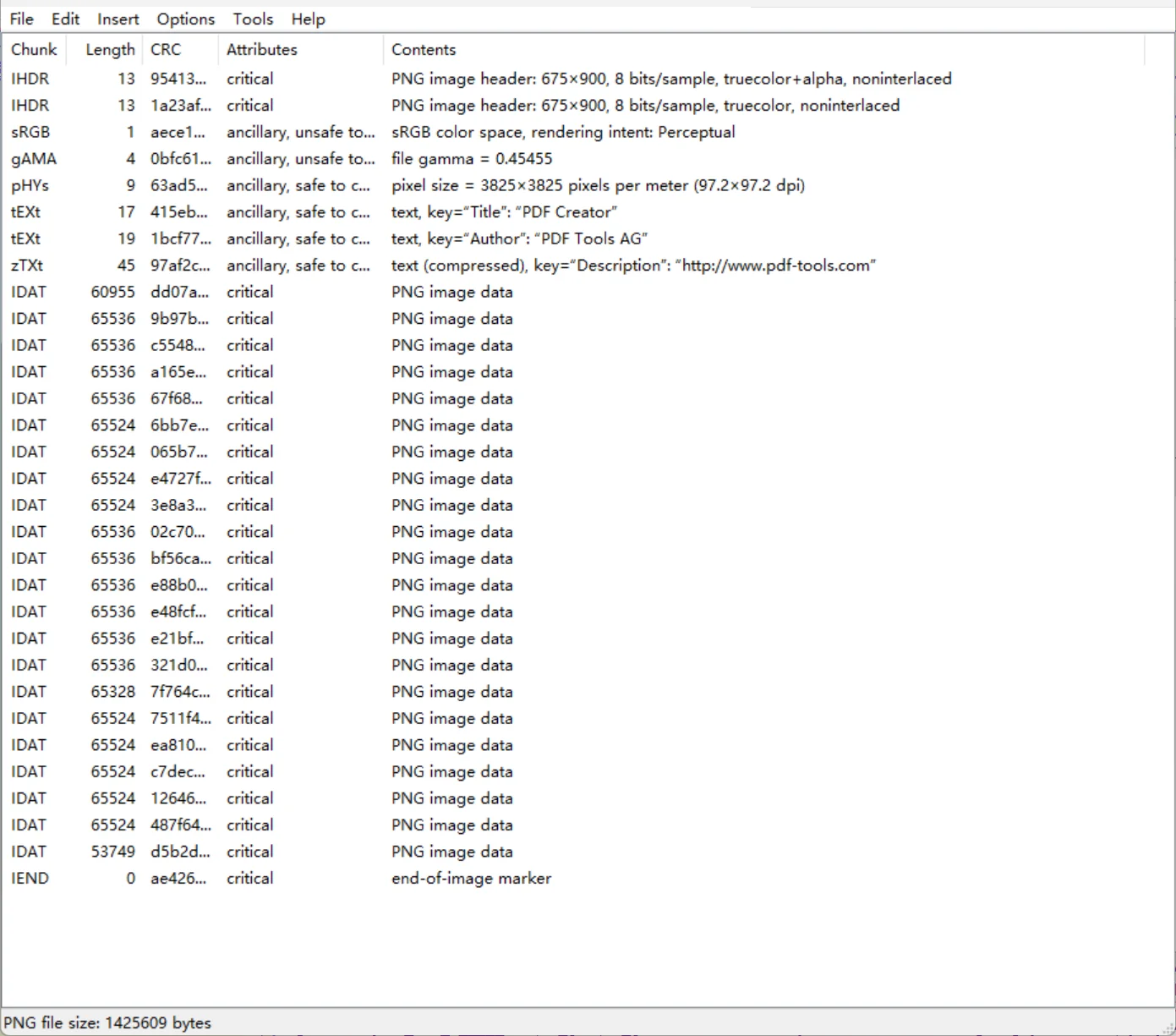
请看,上面的结构有够乱的吧,接下来就需要我们手动调整,将图片提取出来,当看到两个 IHDR,我们就可以确定,这个大杂烩是两张图片放到一起了,结合我们前面说的 png 结构知识点,可以进行组合将两个照片分离出来(附件来源:XYCTF2025-喜欢就说出来
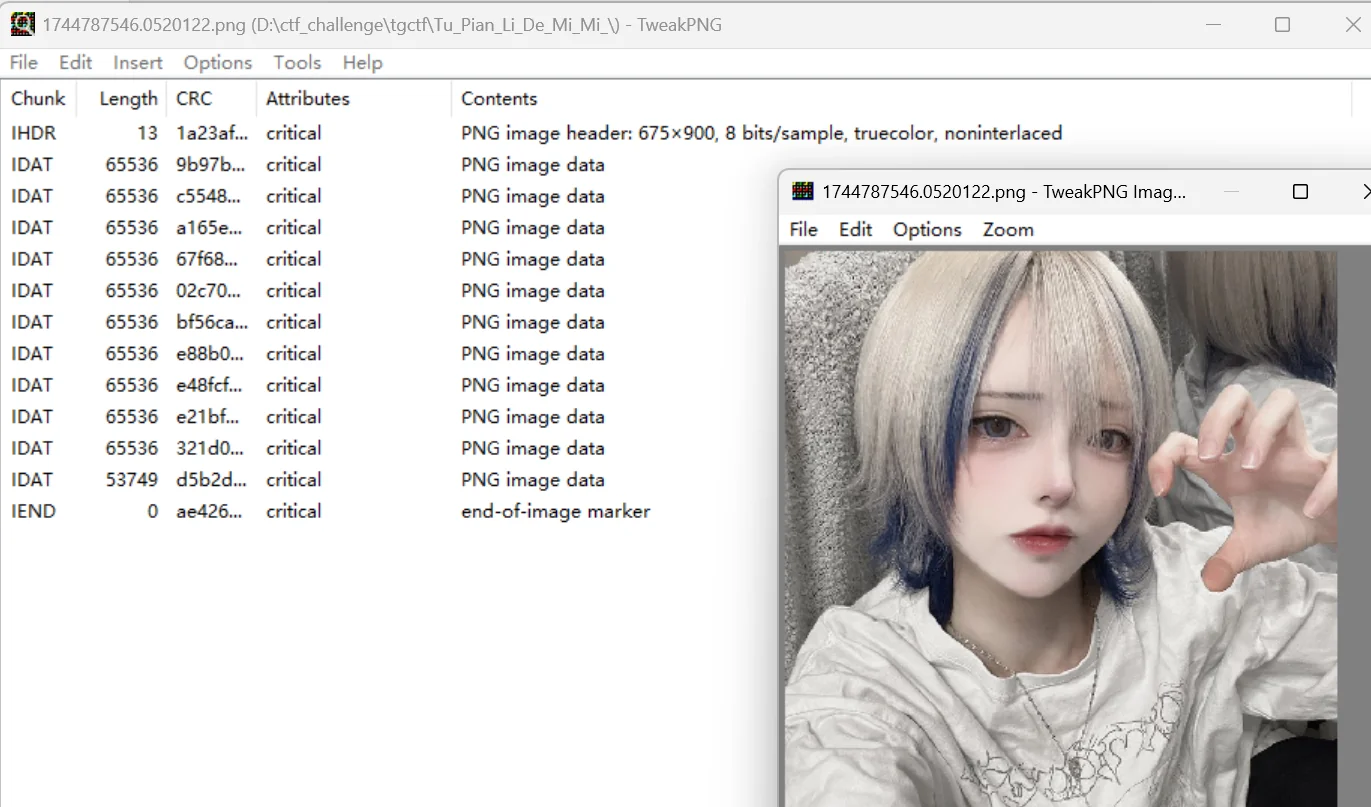
1 | import struct |
这个脚本功能就是说把一个 png 图片的所有数据块罗列出来,本质上和 pngdebugger 工具的作用相同,然后解题的时候建议自己根据脚本输出结果进行分析,如果能锁定哪些数据块异常的话,那就还是使用 tweakpng 工具进行手动敲除吧,我也想过写一个脚本灵活处理不同数据块,但是经过几套脚本的测试,在我看来始终不如 tweakpng 好用,就不在这里显摆我的垃圾脚本了吧
IDAT 块隐写
这里考察了 idat 的压缩特质,(唯一一种 deflate 压缩模式),然后和我前面讨论的那个 idat 大小限制有关,一般来说图片的 idat 块会从第一个 idat 块到倒数第二个 idat 块的大小是一致的,因为这是同一个编译器处理的 png 图片,自然它们底层设计的规则也是一样的,而最后一个 idat 块大小比前面的小,是因为图片数据已经写完了,所以没有填满编译器限制的 idat 的最大阈值。出题师傅考察这种知识点时,会给选手留一点点线索,最直接的便是在图片数据块最后再加个 idat 块,这个时候,我们用 Tweakpng 打开图片的时候,发现在连续的 idat 块中出现了不规则的一个(这里得排除连续 idat 块后面的第一个块,大概率是没有问题滴
感觉有个新的知识考点,如果说我把两个文件的 idat 块放到一起,常见的 idat 隐写是把最后一个 idat 块导出,我这次呢,就选择让两个图片的 idat 最大值一致,然后解题选手需要根据中间不一样的地方,分开两张照片即可
这个知识点的脚本我觉得没有必要单独准备,就用我上面的那个 chunks_check.py 进行分析,然后拿 tweakpng 工具进行处理即可
CRC 宽高爆破
这里的知识点很简单,出题人把 ihdr 块的宽高手动改了,但是他不会改动 crc 校验值的(不排除一些超级逆天题目),然后我们可以进行宽高爆破,爆破难度不大的,正常来说 png 图片的宽高不会过大,我们爆破的难度其实并不大,脚本稍后我会补上
1 | import zlib |
脚本使用方法:python3 crc_weigh_high.py -f xxx.png
脚本原理就和我前面说过的结构那样,然后这里重点是爆破,因为图片的宽高显然不会过大,理由是 ctf 比赛中,很难看到有特别大的分辨率的图片,然后我为了能加快爆破速度,在这里设置了几个常见的分辨率组合
颜色通道隐写
这里也是很重要的考点,由于 png 的无损压缩的特性,而且存储像素是用 RGB,RGBA 等,这种利用颜色通道就能做很多事情了,这里先说 LSB,核心思想如下:
-
每个像素的每个通道(如 R,G,B)用 8 位表示,值为 0 到 255
-
修改最低位(第 0 位)只会使像素值变化 ±1,这个变化很微小,人眼几乎无法察觉
-
通过这种方式,我们可以将文件,字符串等秘密信息诸位嵌入到像素通道的最低位,达到隐藏信息的目的
这里推荐的工具是 stegsolve,zsteg,它们可以帮助我们分析不同颜色通道的内容,从而达到解密的目的
还有种常见的,是 msb 隐写,它和 LSB 相对应,修改的是最高位
但是后来打了几场比赛,发现有些赛题是不会单纯考我们 lsb,msb,他们可能会随机组合颜色通道,这个时候,我们就不好处理了,不清楚应该怎么组合去提取隐藏信息
我的处理思路是写个爆破脚本,然后再记录个常见信息的字典,它会遍历组合所有可能的颜色通道,如果发现出现字典上的信息,会将当前组合返回,接下来我们就着重分析那个通道下的隐藏信息就好了
先在这里分享一下,在任意通道下插入文本或文件的脚本,请注意,插入文本或文件会受到图片大小限制,原因很简单,图片大小就首先限制了我们可以改动的像素点数量,然后为了不让图片变化太大,一般建议我们采用 lsb 隐写,通过最低位隐写会使得我们较难分辨出原图和加密图片的区别,但这也会进一步限制通道隐写插入隐写信息的像素数量
1 | from PIL import Image |
终端差不多是这样的
1 | yolo@Yolo:~/Desktop$ /usr/bin/python3 /home/yolo/Desktop/png_lsb_insert.py |
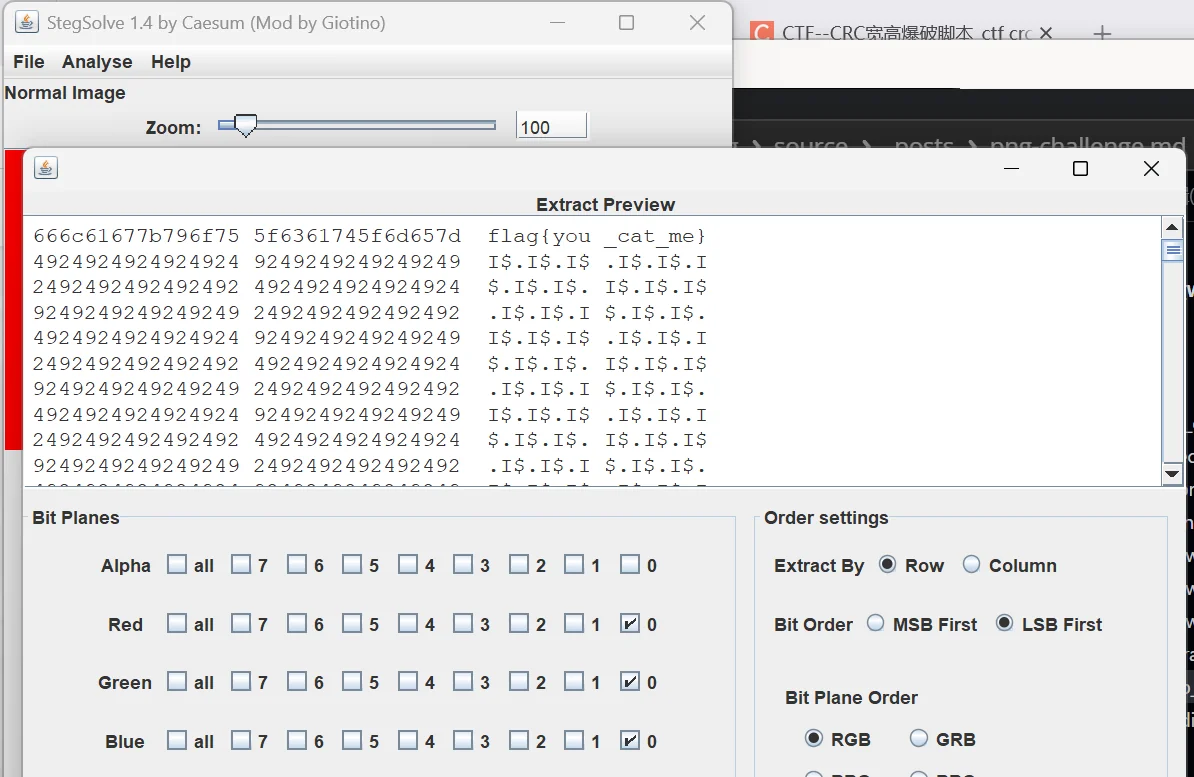
这里我可以说明下,我用 stegsolve 查看过 lsb,发现隐藏信息就在插入信息时设置的通道中
这是直接放文本的
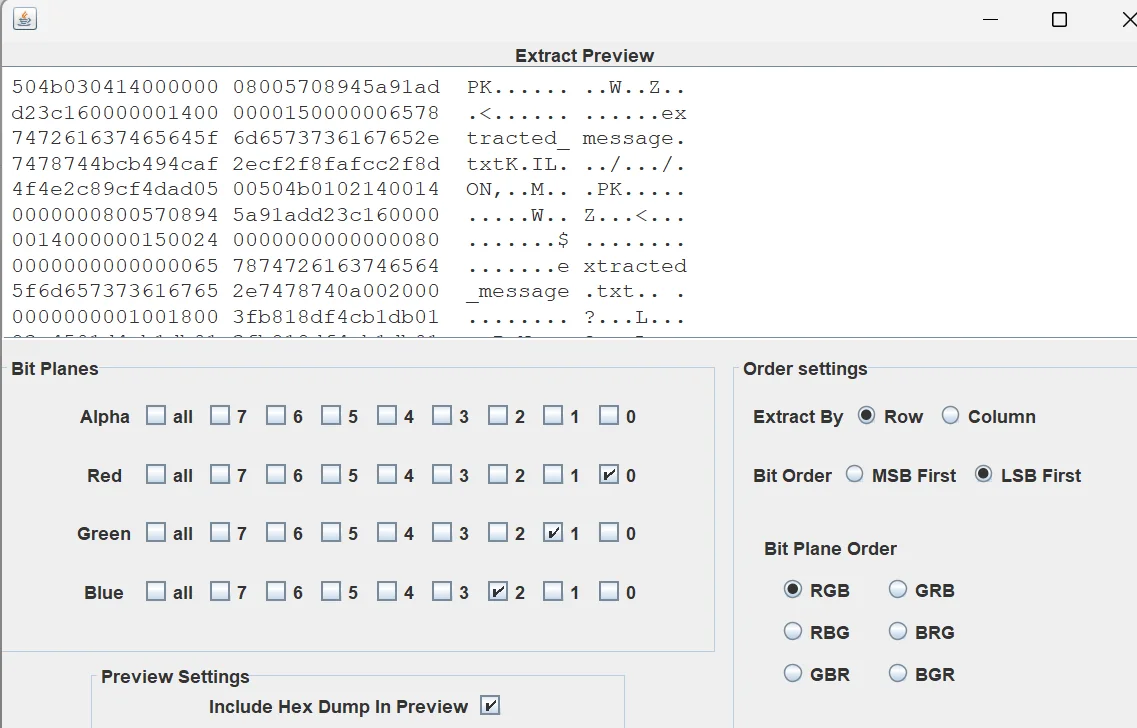
这是直接放文件的
接下来,我的爆破通道提取脚本
1 | from PIL import Image |
使用的时候需要弄个标志字典,给看官举个例子
1 | flag |
然后这是我的终端运行提取脚本的案例
1 | yolo@Yolo:~/Desktop$ /usr/bin/python3 /home/yolo/Desktop/lsb_extracted.py |
我这里的通道组合是按照 RGB 走的,每个颜色分别有 0~7,各 8 个 bit
这样的爆破速度还是蛮快的
相关的脚本我就这样写了吧,在我看来,还是有一些优化部分,比如说把上面的脚本能汇总到一个大的妙妙软件中就好了,不过我现在开发能力还有点差劲,只能在这里留个坑了,等我后面对开发掌握更加深入后,我会把那个集成后的工具链接发到这里的
尾声
这里应该还有个频域攻击、盲水印的知识点没有写到,它们涉及到傅里叶变换、离散余弦变换等好多知识点,还有,它对图片的格式限制较为宽松,所以我后面会单开一篇文章记录这个知识点
说些什么吧!