
曼彻斯特编码 (Manchester Encoding)
曼彻斯特编码是一种在数字通信和数据存储中广泛应用的线路编码技术。其核心特点是在每个数据位的中间时刻引入电平跳变,这个跳变既承载了时钟同步信号,也用于表示数据本身。由于其内置了同步机制,因此也被称为自同步码 (Self-Synchronizing Code) 或 相位编码 (Phase Encoding, PE)。
核心原理
曼彻斯特编码的基本思想是,每一个原始数据比特都被扩展为两个电平状态(或称为码元、chip)来表示。在每个原始比特的持续时间的中心点,信号电平必定会发生一次跳变。
这个在比特中点发生的跳变是曼彻斯特编码的关键,它为接收端提供了精确的时钟同步信息。数据的表示则依赖于这个跳变的方向,或者说,依赖于比特周期内前半部分和后半部分的电平高低组合。
编码规则的两种主要约定
对于标准的曼彻斯特编码,通常有两种广为流传的定义(它们在逻辑值与电平跳变方向的对应关系上正好相反):
-
IEEE 802.3 标准 (常用于以太网)
- 逻辑 ‘1’:表示为在比特周期中间从 低电平跳变到高电平 (LH)。
- 逻辑 ‘0’:表示为在比特周期中间从 高电平跳变到低电平 (HL)。
-
G.E. Thomas 提出的方式 (有时也被视为“经典”约定)
- 逻辑 ‘0’:表示为在比特周期中间从 低电平跳变到高电平 (LH)。
- 逻辑 ‘1’:表示为在比特周期中间从 高电平跳变到低电平 (HL)。
注意:G.E. Thomas 方式定义的标准曼彻斯特编码有时容易与“差分曼彻斯特编码”的概念混淆。关键在于,标准曼彻斯特编码(无论是 IEEE 802.3 还是 G.E. Thomas 约定)的核心是比特中间的跳变方向直接定义了数据值。而差分曼彻斯特编码的数据表示依赖于比特开始处是否有跳变。
关键特性
- 位中间跳变:无论传输的是逻辑 ‘0’ 还是 ‘1’,在每个比特周期的精确中间位置,信号电平都会发生一次转换。这是其最显著的物理特征。
- 同步信息:接收端可以检测这个位中间的跳变来精确地恢复时钟信号,从而与发送端保持同步。这有效解决了像不归零 (NRZ) 编码那样可能因连续的相同数据位而导致同步丢失的问题。
- 无直流分量 (No DC Component):由于每个比特周期内,高电平和低电平占据的时间通常是相等的(因为总有一次跳变),所以信号的平均直流分量趋近于零。这使得曼彻斯特编码的信号可以直接通过不允许有直流分量的传输介质,例如变压器耦合的线路。
- 错误检测能力:由于每个比特都必须有一次中点跳变,如果接收端在预期的中点没有检测到跳变,或者在不应该有跳变的地方(如比特边界处,对于非差分编码而言)检测到跳变,就可以指示可能发生了传输错误。
标准曼彻斯特编码示例
下面我们用表格清晰展示上述两种主要约定的标准曼彻斯特编码规则。我们约定高电平为 ‘1’,低电平为 ‘0’。
表 1: IEEE 802.3 曼彻斯特编码规则
| 原始数据 | 规则说明 (编码定义) | 比特周期 前半段电平 |
比特周期 后半段电平 |
形成的编码 (电平序列 1/0) |
比特中点 电平跳变方向 |
|---|---|---|---|---|---|
| 0 | 信号在比特中点由高跳变到低 | 高 (1) | 低 (0) | 10 |
高 → 低 |
| 1 | 信号在比特中点由低跳变到高 | 低 (0) | 高 (1) | 01 |
低 → 高 |
表 2: G.E. Thomas 曼彻斯特编码规则
| 原始数据 | 规则说明 (编码定义) | 比特周期 前半段电平 |
比特周期 后半段电平 |
形成的编码 (电平序列 1/0) |
比特中点 电平跳变方向 |
|---|---|---|---|---|---|
| 0 | 信号在比特中点由低跳变到高 | 低 (0) | 高 (1) | 01 |
低 → 高 |
| 1 | 信号在比特中点由高跳变到低 | 高 (1) | 低 (0) | 10 |
高 → 低 |
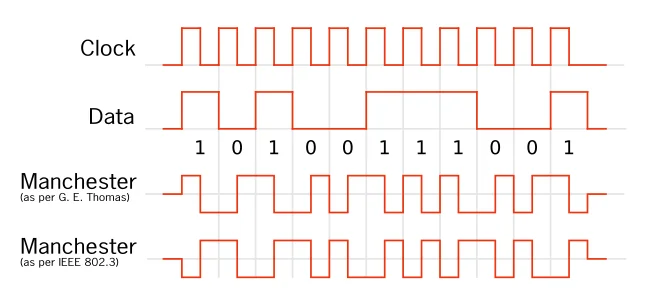
上图是根据两种规定的曼彻斯特编码方式
差分曼彻斯特编码 (Differential Manchester Encoding)
差分曼彻斯特编码是曼彻斯特编码的一种重要变种。它同样在每个比特周期的中间有一次电平跳变(主要用于时钟同步),但其表示数据的方式与标准曼彻斯特编码不同。
核心原理与编码规则
差分曼彻斯特编码通过比特周期的起始处是否存在电平跳变来表示数据:
- 逻辑 ‘0’:通过在比特周期的开始处引入一次电平跳变来表示(相对于前一个比特周期的结束电平而言)。
- 逻辑 ‘1’:通过在比特周期的开始处不发生电平跳变来表示(即当前比特的起始电平与前一个比特的结束电平相同)。
无论数据是 ‘0’ 还是 ‘1’,比特周期的中间仍然必须有一次电平跳变以维持时钟同步。这意味着差分曼彻斯特编码的每个比特单元的两个半周期电平也总是相反的。
关键特性
- 自同步性:与标准曼彻斯特编码一样,通过比特中点的固定跳变实现。
- 对信号极性不敏感(部分情况):由于数据是通过“变化”或“无变化”来表示的,而不是绝对的电平高低或跳变方向,因此在某些情况下,如果整个信号流的极性被意外反转,差分编码仍然可以被正确解码(但这取决于接收器的具体实现)。
- 需要初始参考:解码第一个比特时,需要知道数据流开始之前的线路电平状态,作为判断第一个比特开始处是否有跳变的参考。
- 无直流分量:与标准曼彻斯特编码类似。
差分曼彻斯特编码示例
下表展示了差分曼彻斯特编码的过程。注意,当前比特的编码依赖于前一个比特的结束电平。
| 原始数据 (D) | 前一比特 结束电平 (Prev_End) |
当前比特开始处 是否有跳变? |
当前比特 前半段电平 (S1) |
当前比特 后半段电平 (S2) (S2 必定与 S1 相反) |
形成的编码 (电平序列 S1S2) |
|---|---|---|---|---|---|
| (初始状态) | (假设为高 ‘1’) | - | - | - | - |
| 0 | 高 (‘1’) | 是 (S1≠Prev_End) | 低 (‘0’) | 高 (‘1’) | 01 |
| 1 | 高 (‘1’) | 否 (S1=Prev_End) | 高 (‘1’) | 低 (‘0’) | 10 |
| 0 | 低 (‘0’) | 是 (S1≠Prev_End) | 高 (‘1’) | 低 (‘0’) | 10 |
| 1 | 低 (‘0’) | 否 (S1=Prev_End) | 低 (‘0’) | 高 (‘1’) | 01 |
(上表示例中,S2 的选择是为了确保中点跳变,例如若 S1 为低,则 S2 为高,反之亦然。实际波形会自然形成这种中点跳变。)
曼彻斯特编码的解码过程
无论是标准曼彻斯特编码还是差分曼彻斯特编码,其解码过程都依赖于对信号中电平跳变的精确检测。
1. 时钟恢复与同步 (Clock Recovery and Synchronization)
- 寻找跳变:解码器首先持续检测输入信号中的电平跳变。对于这两种曼彻斯特编码,每个比特周期的中间都保证有一次跳变。
- 同步时钟:利用这些周期性的中点跳变,接收端可以调整其内部时钟,使其与发送数据的速率和相位同步。硬件实现中常使用锁相环 (PLL)。
- 确定比特边界:一旦时钟同步,接收端就能准确地划分出每个曼彻斯特编码符号(代表一个原始数据位)的起始和结束时刻,以及关键的比特周期中点。
2. 识别比特内的电平模式/跳变特征
对于每一个已确定边界的编码符号:
- 标准曼彻斯特解码:
- 方法一 (检测中点跳变方向):在比特周期的中间时刻,判断电平是从高跳到低 (H→L),还是从低跳到高 (L→H)。
- 方法二 (采样前后半段电平):分别采样比特周期前半段和后半段的电平,比较两者以确定是 “高-低”(HL) 模式还是 “低-高”(LH) 模式。
- 差分曼彻斯特解码:
- 获取当前比特周期的第一个半周期电平 (S1)。
- 获取前一个比特周期的第二个半周期电平 (即前一比特的结束电平)。
- 比较 S1 与前一比特的结束电平,判断当前比特开始时是否发生了跳变。
- 同时,必须验证当前比特的 S1 和 S2 是否相反,以确认比特内中点跳变的存在。如果 S1 和 S2 相同,则这是一个无效的差分曼彻斯特编码符号。
3. 应用编码规则进行解码
根据已知的编码标准(IEEE 802.3, G.E. Thomas, 或差分曼彻斯特)和上一步识别出的特征,将每个编码符号转换回原始的 ‘0’ 或 ‘1’。
- IEEE 802.3:
- 高 → 低 (HL /
10) 解码为 ‘0’。 - 低 → 高 (LH /
01) 解码为 ‘1’。
- 高 → 低 (HL /
- G.E. Thomas:
- 低 → 高 (LH /
01) 解码为 ‘0’。 - 高 → 低 (HL /
10) 解码为 ‘1’。
- 低 → 高 (LH /
- 差分曼彻斯特:
- 比特开始处有电平跳变,解码为 ‘0’。
- 比特开始处无电平跳变,解码为 ‘1’。
- (解码第一个比特时,需要知道数据流开始前的信号电平作为初始参考。)
4. 处理数据流
对接收到的整个曼彻斯特编码信号流,逐个编码符号重复上述同步、识别和解码步骤,最终将解码出的所有原始数据位按顺序排列,恢复出原始信息。
Summary
TIP
这里给没有理解清楚的小白开个小灶,如果理解深刻的话,可以直接翻阅我下面写的 python 脚本以及小福利哈
相信上面的内容还是对小白不够友好,我这里做个总结,把过程再剖析下,希望大家能理解清楚
电脑是不直接认识字母’a’的,它只认识’0’,’1’,所以我们需要先把’a’变成标准的二进制暗号
在 ASCII 表中,字母 a 的十进制为 97,转换成 8 位二进制数后,就是01100001
这里的三种编码方式,我会选择一个很通俗易懂的例子:手电筒规则
IEEE 802.3 编码
想象一下,我们现在要用手电筒发送一串 01100001 给朋友,然后我们的手电筒只有两种状态:
- 亮(高电平,用 1 代表)
- 低(低电平,用 0 代表)
然后 IEEE 802.3 曼彻斯特编码的规则是:
- 要发送原始数据 0 时,我们需要让手电筒先亮一段时间,然后在发送这个 0 的时间段的正中间,立刻把手电筒变成灭,所以,0 的信号模式是“亮-灭”(即 10)
- 要发送原始数据 1 时,我们需要让手电筒先灭一段时间,然后在发送这个 1 的时间段的正中间,立刻把手电筒变成亮,所以,1 的信号模式是“灭-亮”(即 01)
接下来看那个字母 a,它的二进制编码是01100001
过程如下:
- 发送第一个比特
0:- 规则:
0→ “亮-灭” (10) - 手电筒动作:先亮,后灭。
- 编码后的电平:
10
- 规则:
- 发送第二个比特
1:- 规则:
1→ “灭-亮” (01) - 手电筒动作:先灭,后亮。
- 编码后的电平:
01
- 规则:
- 发送第三个比特
1:- 规则:
1→ “灭-亮” (01) - 手电筒动作:先灭,后亮。
- 编码后的电平:
01
- 规则:
- 发送第四个比特
0:- 规则:
0→ “亮-灭” (10) - 手电筒动作:先亮,后灭。
- 编码后的电平:
10
- 规则:
- 发送第五个比特
0:- 规则:
0→ “亮-灭” (10) - 手电筒动作:先亮,后灭。
- 编码后的电平:
10
- 规则:
- 发送第六个比特
0:- 规则:
0→ “亮-灭” (10) - 手电筒动作:先亮,后灭。
- 编码后的电平:
10
- 规则:
- 发送第七个比特
0:- 规则:
0→ “亮-灭” (10) - 手电筒动作:先亮,后灭。
- 编码后的电平:
10
- 规则:
- 发送第八个比特
1:- 规则:
1→ “灭-亮” (01) - 手电筒动作:先灭,后亮。
- 编码后的电平:
01
- 规则:
接下来将上面编码后的电平记录出来 10 01 01 10 10 10 10 01
感觉还算简单吧
G.E.Thomas 曼彻斯特编码
同样,我们使用字母 a 进行研究
G.E.Thomas 曼彻斯特编码的手电筒规则如下
- 要发送原始数据
0时:我们需要让手电筒先 灭 一小段时间,然后在发送这个0的时间段的 正中间,立刻把手电筒变成 亮。所以,0的信号模式是 “灭-亮”(即01)。 - 要发送原始数据
1时:我们需要让手电筒先 亮 一小段时间,然后在发送这个1的时间段的 正中间,立刻把手电筒变成 灭。所以,1的信号模式是 “亮-灭”(即10)。
这样的话,我们发送完整的数据的过程是
- 发送第一个比特
0:- 规则 (G.E. Thomas):
0→ “灭-亮” (01) - 手电筒动作:先灭,后亮。
- 编码后的电平:
01
- 规则 (G.E. Thomas):
- 发送第二个比特
1:- 规则 (G.E. Thomas):
1→ “亮-灭” (10) - 手电筒动作:先亮,后灭。
- 编码后的电平:
10
- 规则 (G.E. Thomas):
- 发送第三个比特
1:- 规则 (G.E. Thomas):
1→ “亮-灭” (10) - 手电筒动作:先亮,后灭。
- 编码后的电平:
10
- 规则 (G.E. Thomas):
- 发送第四个比特
0:- 规则 (G.E. Thomas):
0→ “灭-亮” (01) - 手电筒动作:先灭,后亮。
- 编码后的电平:
01
- 规则 (G.E. Thomas):
- 发送第五个比特
0:- 规则 (G.E. Thomas):
0→ “灭-亮” (01) - 手电筒动作:先灭,后亮。
- 编码后的电平:
01
- 规则 (G.E. Thomas):
- 发送第六个比特
0:- 规则 (G.E. Thomas):
0→ “灭-亮” (01) - 手电筒动作:先灭,后亮。
- 编码后的电平:
01
- 规则 (G.E. Thomas):
- 发送第七个比特
0:- 规则 (G.E. Thomas):
0→ “灭-亮” (01) - 手电筒动作:先灭,后亮。
- 编码后的电平:
01
- 规则 (G.E. Thomas):
- 发送第八个比特
1:- 规则 (G.E. Thomas):
1→ “亮-灭” (10) - 手电筒动作:先亮,后灭。
- 编码后的电平:
10
- 规则 (G.E. Thomas):
总结上面的所有电平信号:0110100101010110
小 Summary
这里给出我的理解,IEEE 802.3 编码结构是时钟+数据,也就是说,每两个数字中,一直是状态量+数据值,然后 G.E.Thomas 就不一样了,或者说恰恰相反,它的结构就是先数据值再状态量
差分曼彻斯特编码
这个类型就和前两个差距稍微明显了一点点
差分曼彻斯特编码的规则更加关注“变化”本身:
- 比特中间的跳变依然存在:和标准曼彻斯特编码一样,在每个原始比特的持续时间的正中间,手电筒的状态(亮/灭)必须反转一次。这是为了保持时钟同步。
- 数据的表示看比特开始时:
- 要发送原始数据
0时:在开始发送这个 ‘0’ 的那一刻,手电筒的状态必须与上一个比特结束时的状态相反(即发生一次电平跳变)。 - 要发送原始数据
1时:在开始发送这个 ‘1’ 的那一刻,手电筒的状态必须与上一个比特结束时的状态相同(即不发生电平跳变)。
- 要发送原始数据
关键点:差分编码需要知道“上一个比特结束时的状态”是什么。那么对于第一个要发送的比特,它“上一个比特”是什么呢?我们需要一个初始状态的约定。
这种编码关注的点其实是跳变,如果数据是 0 的话,我们就必须在最开始跳变一次,如果是 1 的话,我们就不能在最开始跳变
先看看发送数据的过程(假设初始手电筒是亮的,也就是说状态量为 1)
- 发送第一个比特
0:- 规则:发送 ‘0’ 时,比特开始处要有跳变。
- 当前手电筒是 亮 (‘1’)。为了有跳变,这个比特开始时手电筒要变成 灭 (‘0’) (这是比特的第一半状态)。
- 比特中间必须再次跳变:所以后半段手电筒从 灭(‘0’) 变成 亮 (‘1’)。
- 编码后的电平:
01。 - 更新状态:这个比特结束时,手电筒是 亮 (‘1’)。
- 发送第二个比特
1:- 规则:发送 ‘1’ 时,比特开始处无跳变。
- 上一个比特结束时手电筒是 亮 (‘1’)。为了无跳变,这个比特开始时手电筒保持 亮 (‘1’) (这是比特的第一半状态)。
- 比特中间必须再次跳变:所以后半段手电筒从 亮(‘1’) 变成 灭 (‘0’)。
- 编码后的电平:
10。 - 更新状态:这个比特结束时,手电筒是 灭 (‘0’)。
- 发送第三个比特
1:- 规则:发送 ‘1’ 时,比特开始处无跳变。
- 上一个比特结束时手电筒是 灭 (‘0’)。为了无跳变,这个比特开始时手电筒保持 灭 (‘0’)。
- 比特中间跳变:后半段变成 亮 (‘1’)。
- 编码后的电平:
01。 - 更新状态:这个比特结束时,手电筒是 亮 (‘1’)。
- 发送第四个比特
0:- 规则:发送 ‘0’ 时,比特开始处要有跳变。
- 上一个比特结束时手电筒是 亮 (‘1’)。为了有跳变,这个比特开始时变成 灭 (‘0’)。
- 比特中间跳变:后半段变成 亮 (‘1’)。
- 编码后的电平:
01。 - 更新状态:这个比特结束时,手电筒是 亮 (‘1’)。
- 发送第五个比特
0: (同上,前一个结束为亮’1’)- 编码后的电平:
01。 - 更新状态:结束时为 亮 (‘1’)。
- 编码后的电平:
- 发送第六个比特
0: (同上,前一个结束为亮’1’)- 编码后的电平:
01。 - 更新状态:结束时为 亮 (‘1’)。
- 编码后的电平:
- 发送第七个比特
0: (同上,前一个结束为亮’1’)- 编码后的电平:
01。 - 更新状态:结束时为 亮 (‘1’)。
- 编码后的电平:
- 发送第八个比特
1:- 规则:发送 ‘1’ 时,比特开始处无跳变。
- 上一个比特结束时手电筒是 亮 (‘1’)。为了无跳变,这个比特开始时保持 亮 (‘1’)。
- 比特中间跳变:后半段变成 灭 (‘0’)。
- 编码后的电平:
10。 - 更新状态:这个比特结束时,手电筒是 灭 (‘0’)。
总结下所有的电平信号,得到了 0110010101010110
希望上面的 Summary 能帮助到大家
Python 脚本 (用于编码)
以下是一个 python 脚本,它可以读取任意路径的文件,任意格式,然后可以自定义三种曼彻斯特编码模式,以及选择是否进行逆序处理
还有 ASCII 预览呢
1 | import os |
Python 脚本 (用于解码)
以下是一个 Python 脚本,它可以读取包含 ‘0’ 和 ‘1’ 字符(代表编码后的电平状态)的文件,并根据用户选择的曼彻斯特编码标准(包括差分曼彻斯特)进行解码,同时提供 ASCII 预览和逆序选项。
1 | import os |
小福利(网鼎杯-朱雀组-Misc1)
特别安利平台 CTF+
这是题目链接https://www.ctfplus.cn/problem-detail/1863418368669782016/description
下载附件,发现只有 01 的字符串,最开始我以为是二进制转 ASCII 呢,可惜不是
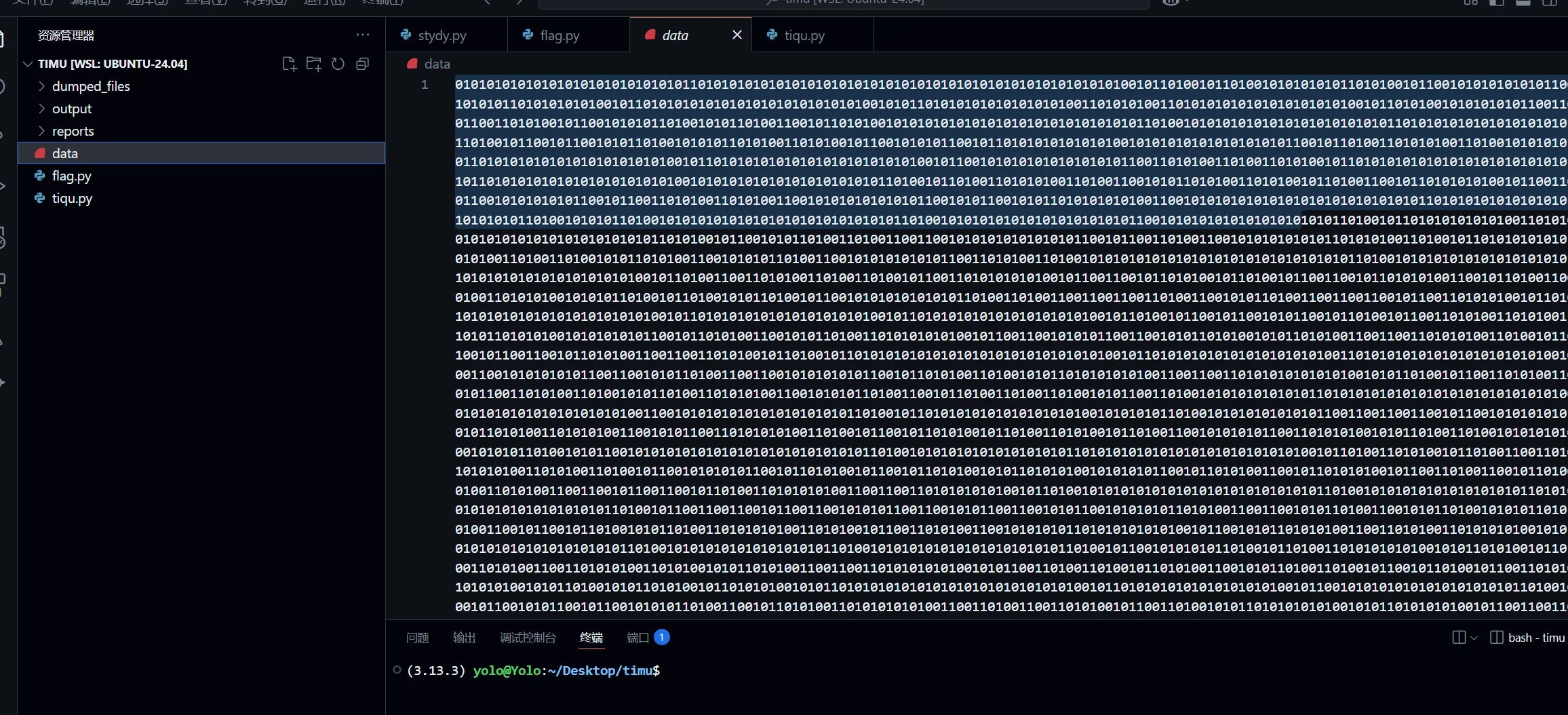
后来研究了下,发现是曼彻斯特编码😫
鉴于曼彻斯特就那么几种编码而已,我就索性一个一个尝试了呗,就三个,尝试过前两个,都没看出什么东西,

但是在差分这里出现了特别特殊的东西,PK
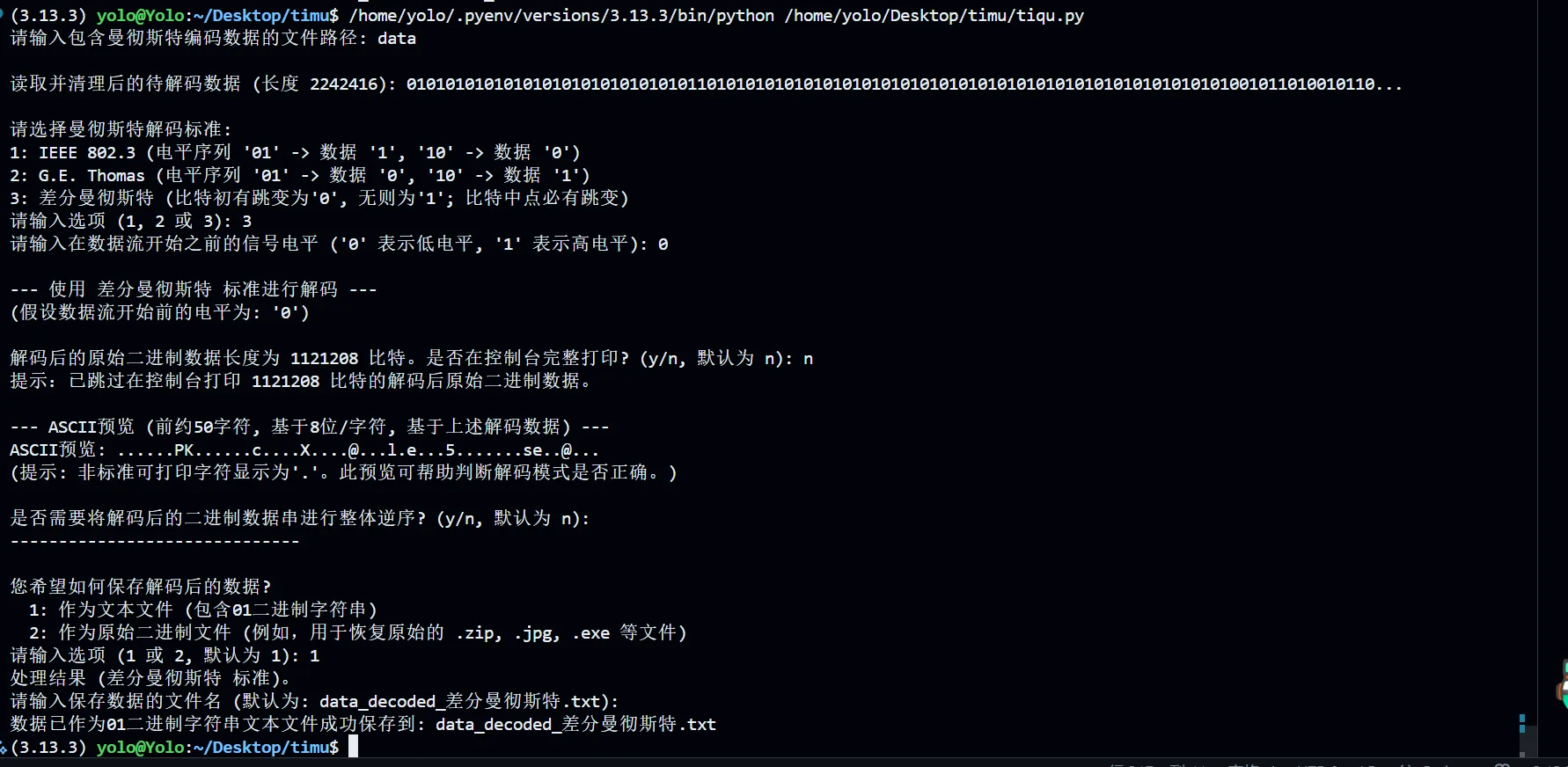
就先提取下来好了,我现在检查下这个压缩包
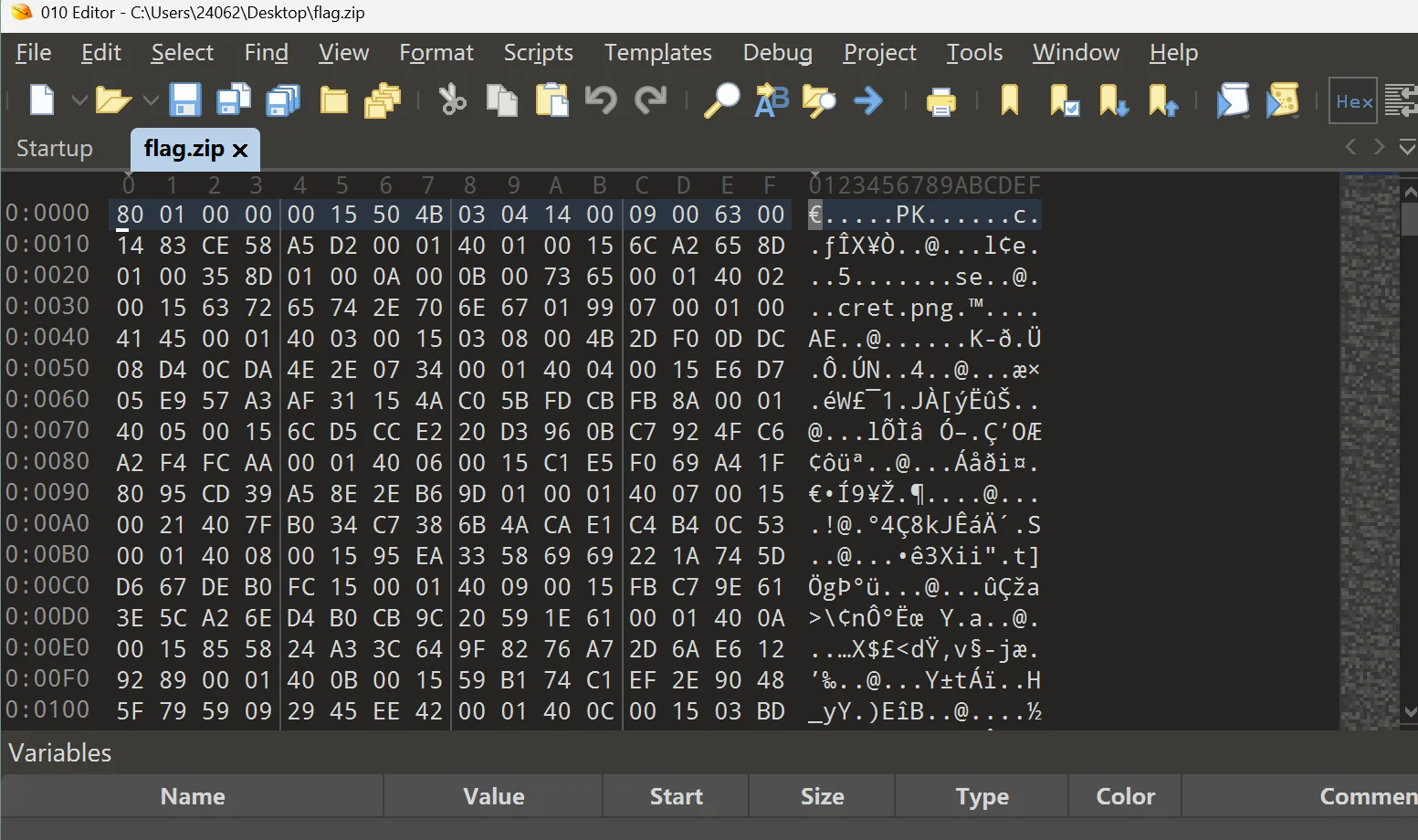
有些地方有点点小问题,我看着改改
如果没有记住 zip 的详细结构的话,这里有个小技巧,就是随便压缩个文件,一一比对
来看看文件结尾
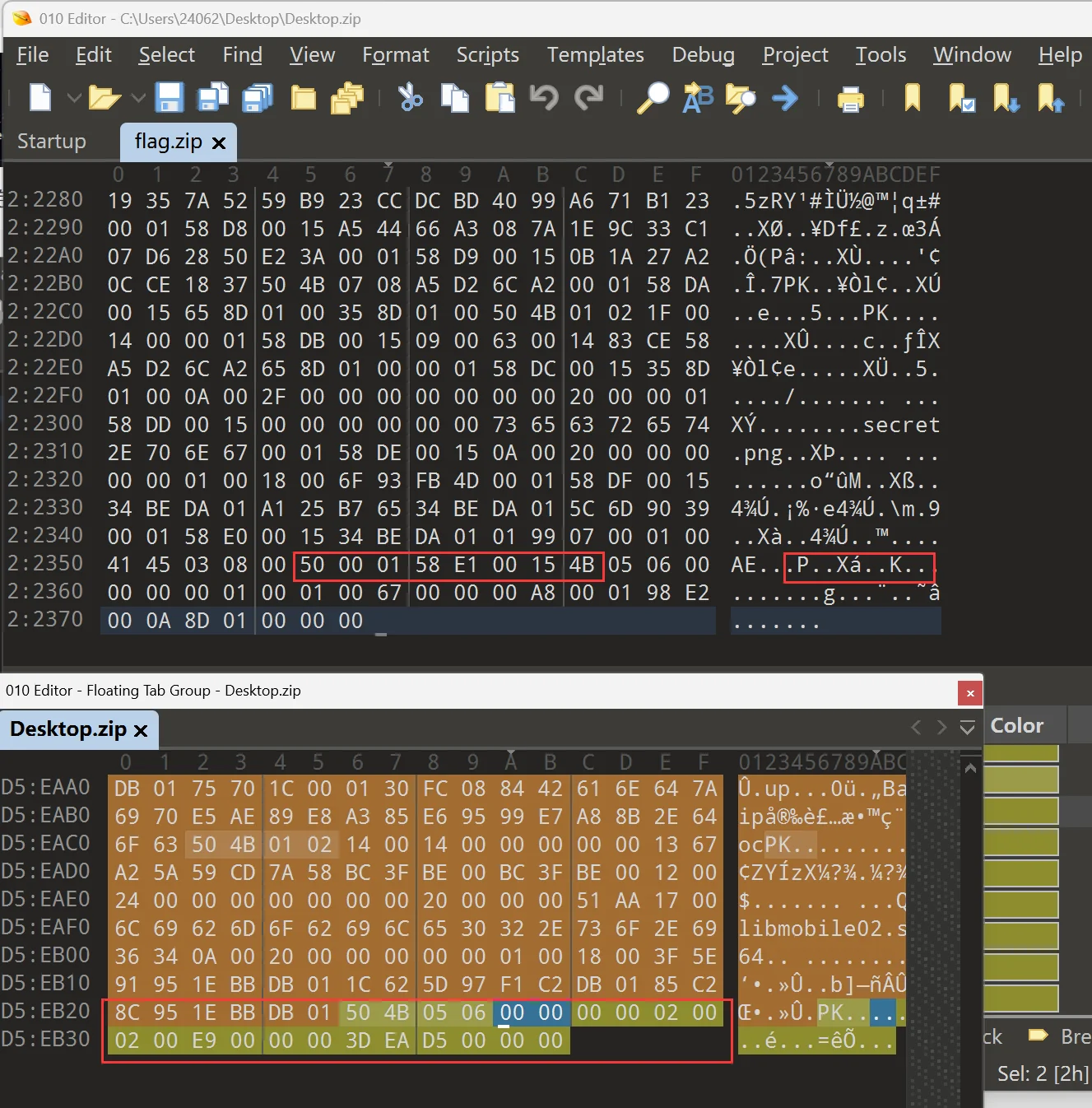
但是呢,我越改越感觉不对,一个是工作量太大了吧,另一个是不太好盯这里的差异,不过我发现了一点,结合最开头的未知 6 字节,加上这里插入的 6 字节,出题人这里插入的数据还挺规律的,那就先查看下整个压缩包的 16 进制的特殊地方吧,这里我选择一行按照 44 个字节输出,理由是 6+16+6+16,这里的 16 是因为我发现最前面的 zip 压缩包的魔数是 16 字节没有问题的,maybe 这样可以将规律找出来
1 | import binascii |
运行完脚本后,就得到了很显然的规律
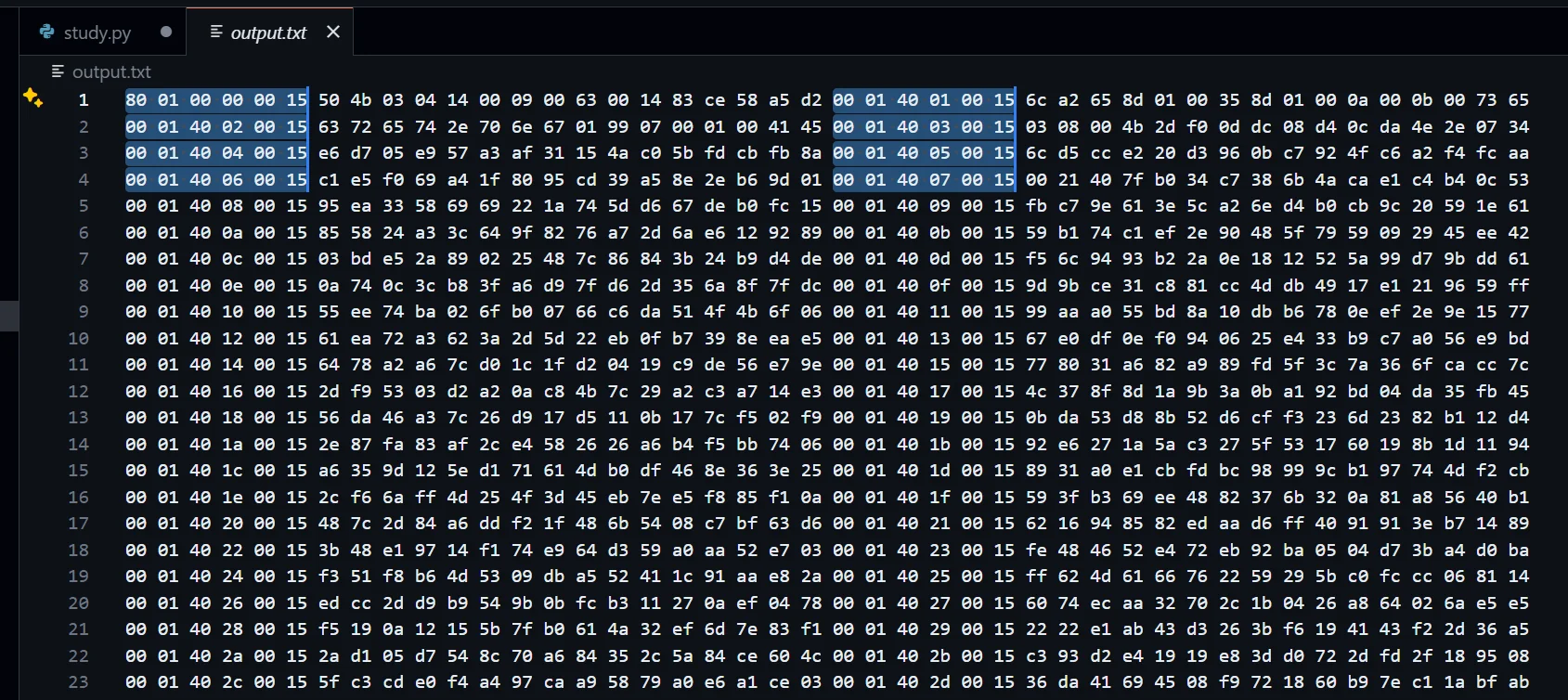
但是这里并不允许我使用查找功能替换掉那些多余数据,那就继续 6+16+6+16 咯
1 | def process_binary_file_by_position(input_binary_path, output_binary_path): |
这样处理后,我的压缩包就能打开了
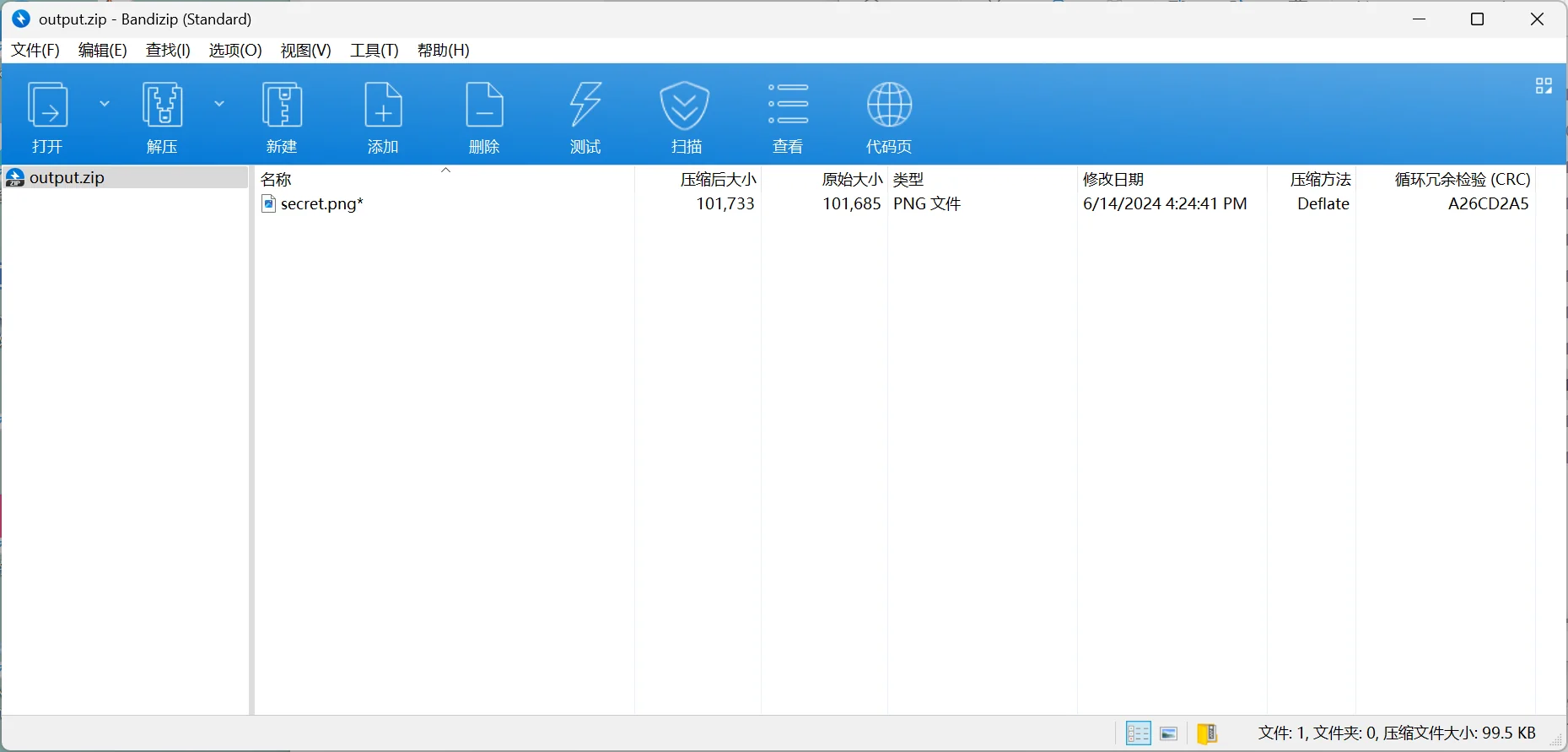
这里发现是个加密压缩包,检查完并不是伪加密,明文攻击 png 魔数这些攻击类型,那就只能是密码爆破了,希望密码能设置简单一点点
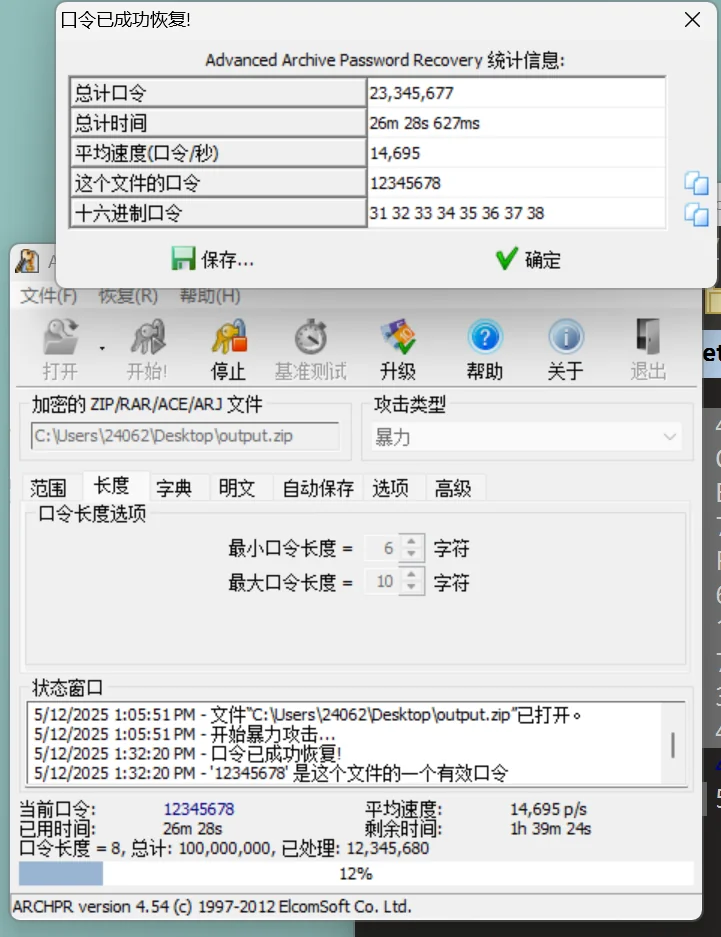
得到密码:12345678
用 010 editor 查看 secret.png
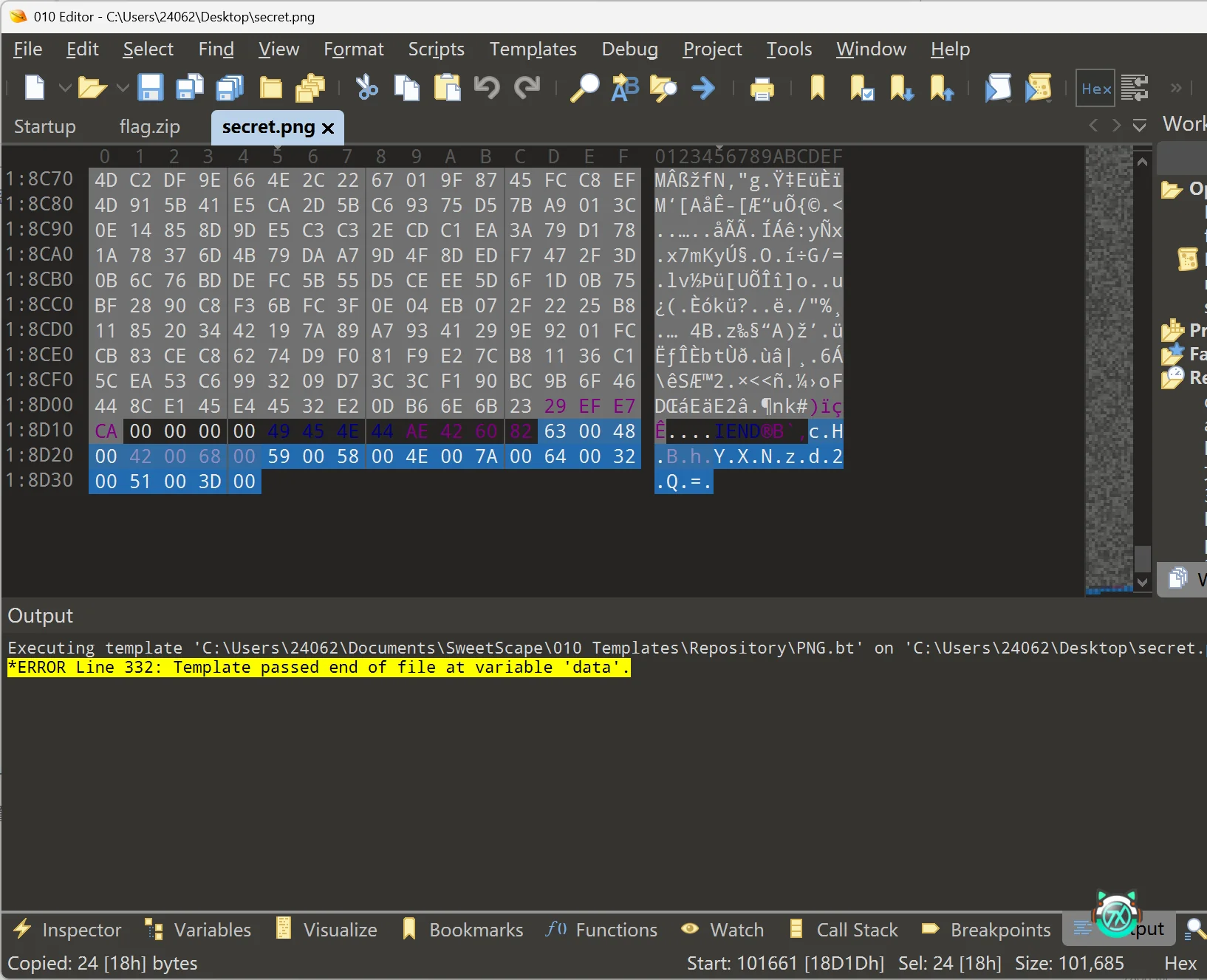
发现末尾插入了串 base64 编码,解码后得到
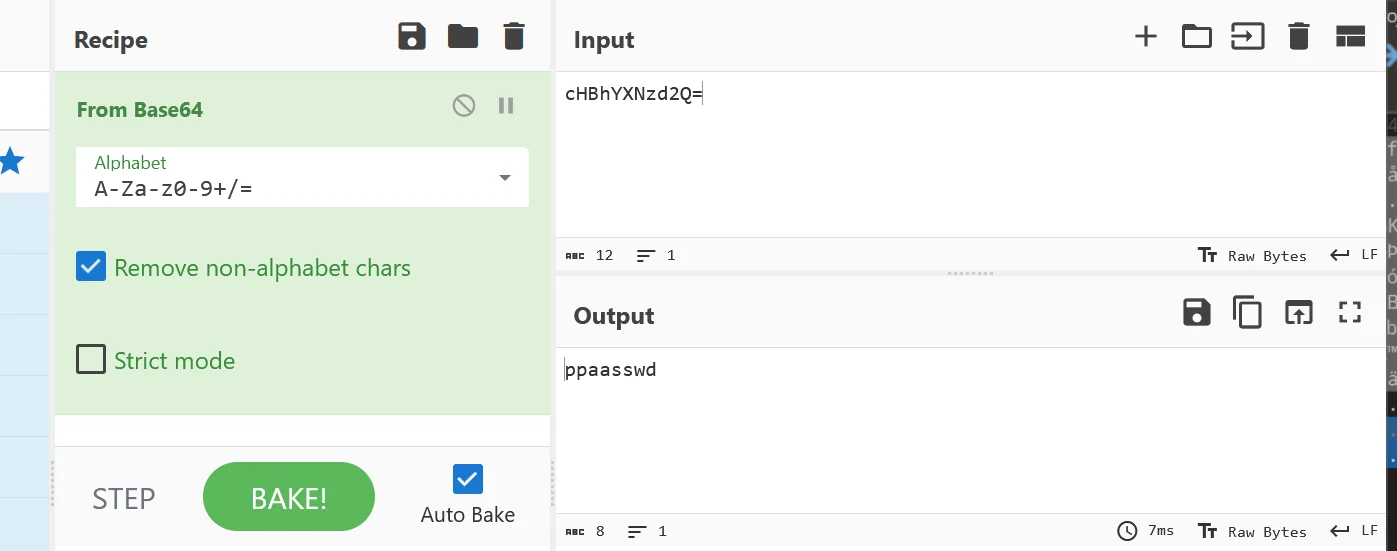
既然是 png 的某一种带 key 加密,这里可以尝试PixelJihad
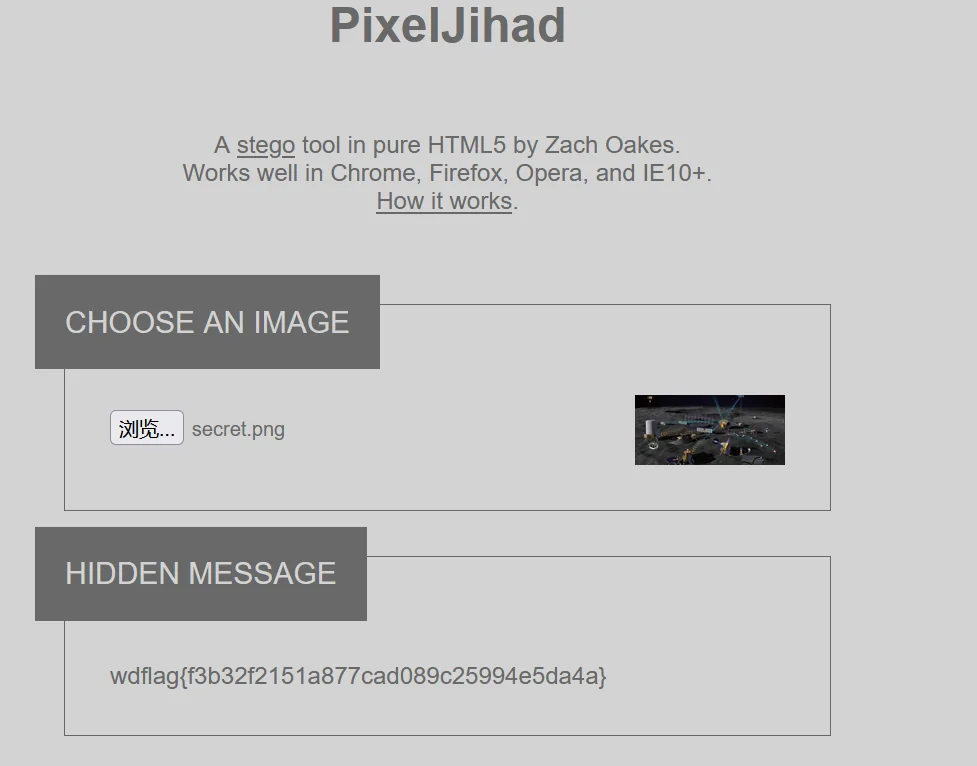
得到 flag:wdflag{f3b32f2151a877cad089c25994e5da4a}
补充(曼彻斯特在音频中的应用)
在平常 ctf 比赛中,会遇到 wav 这类音频隐写中出现这种隐写
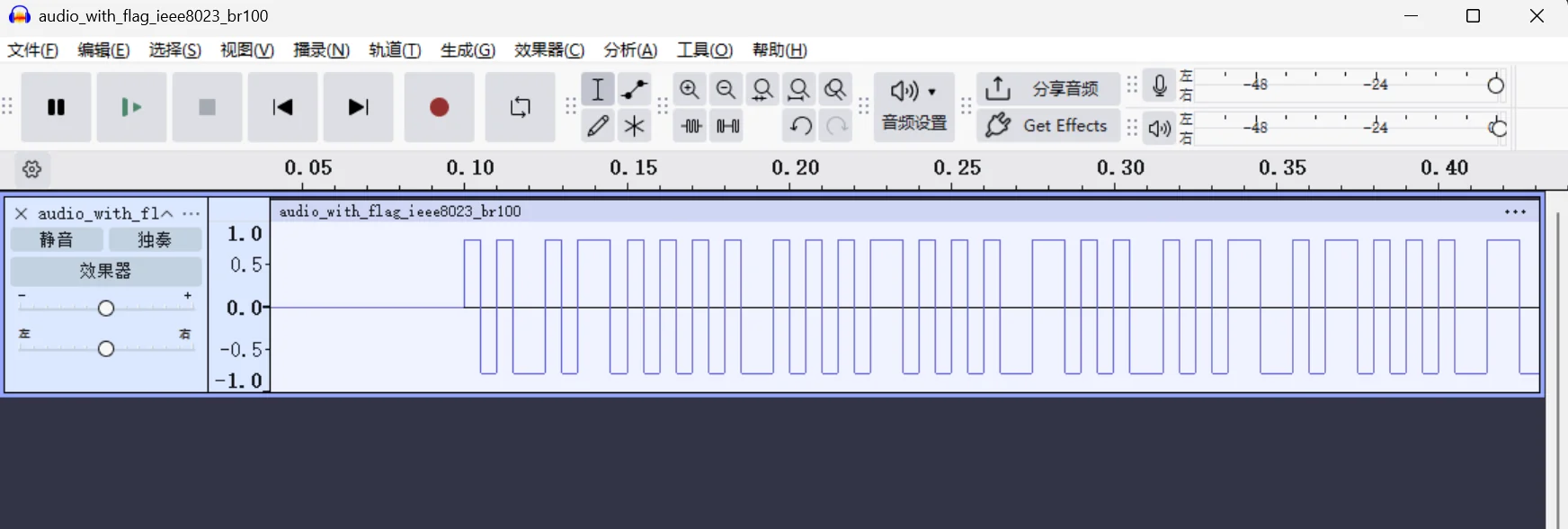
题目分析
先说明怎么看这种波形图,其实很简单,主要看最上面的时间轴
先放足够大
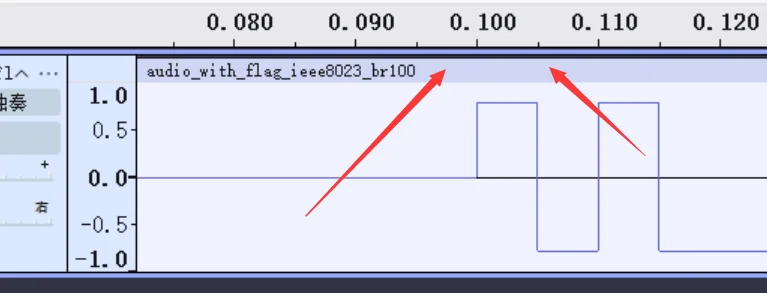
先关注这个波形图的起点,以时间轴为标准,看样子是 0.1s 开始的,然后看第二个箭头,它可以帮助我们找到电平持续长度,这个知识点我上面对原理说明中提到过,通过观察,可以判断最小 bit 位的一半是 0.105-0.100=0.005,所以最小电平持续时间应该是 0.005*2=0.01s
注意
这里的最小 bit 位不一定是最前面看到的那个,我们要综合看完整的波形图,找出里面最短的波形就是了,还有啊,这里的电平是要满足一个周期长度的,所以 0.005 仅仅是半个周期,要记得 ×2
提取脚本及其用法
这里直接给出我搓的提取脚本,对了,原理部分我就不重复了,我主要是按照我上面的原理写的
1 | import scipy.io.wavfile as wavfile |
先说说怎么使用我的代码

在终端面板使用
1 | python tiqu.py xxx.wav(指向待解密的音频文件) all(指定解码模式) (<可选> -s 指定开始时间 -b 指定单个bit的持续时间 -t 指定音频信号的阈值 -dil 如果是差分曼彻斯特,需要指定初始边界电平(0/1) -o 指定输出文件的文件名 -eb 指定解码的长度 -sdt 指定字节数阈值) |
会不会太过自由,不太好用?
这里拿样本举个例子,在上面的题目分析中,我们知道开始时间为 0.1,最小 bit 电平长度为 0.01,然后根据文件名,可以判断这个音频是 IEEE8023 编码模式,那么脚本就应该这样用
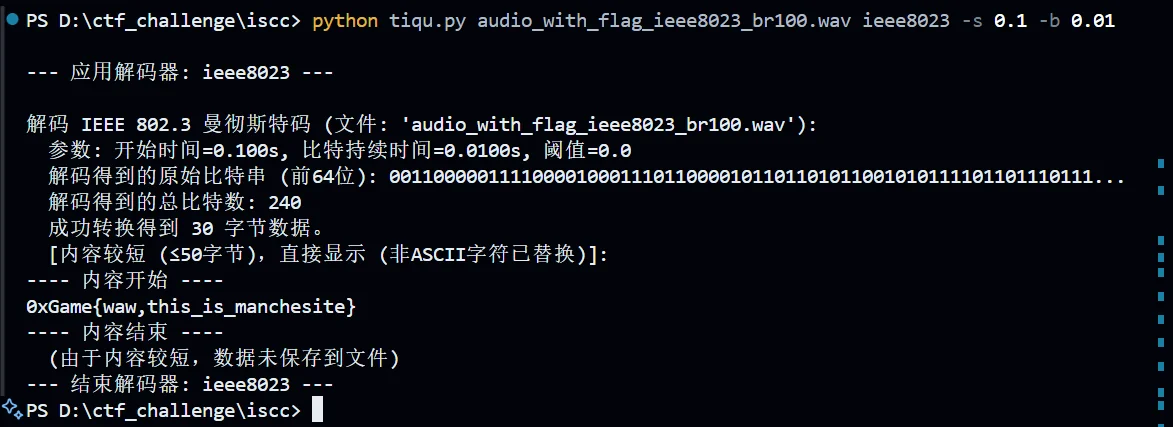
如果题目没有说明解码模式,这里我们可以直接用 all,将多种模式都尝试一遍
1 | PS D:\ctf_challenge\iscc> python tiqu.py audio_with_flag_ieee8023_br100.wav all |
然后可以观察到,我这次甚至没有指定-s 和-b,这是因为这个音频很普通,甚至没有插入其他杂乱的音频信息,我就按照默认的处理了(当然,掌握波形读图能力是必须的,就按照题目分析部分的那样,拿到一些参数)
这个脚本的亮点是:自由度足够高,可在终端任意输入参数;模式丰富,除了 IEEE 802.3、G.E.Thomas 和差分曼彻斯特编码,还有一种非标准曼彻斯特编码(点名 ISCC,它有一道 misc 题目,我分析过后,发现不属于任何一种标准曼彻斯特编码);然后脚本足够人性化,它会把提取出来的数据,先进行预览,将前 50 个字符转换成 ASCII,让我们观察有没有重要信息,如果数据太多,就会保存在文件中去,如果太少,就直接输出终端
编码脚本及其用法
一样是个很 nice 的脚本呢
1 | import numpy as np |
这里详细说说使用方法

1 | python create.py -ds '10110'(或者-if 指定要隐藏的内容) -o 指定输出文件基础名 -et all(指定编码模式) (这后面是可选的:-br 指定比特率 -sr 指定采样率 -a 指定信号浮点幅度 -sl 指定前后静音时间) |
这里一样举个例子
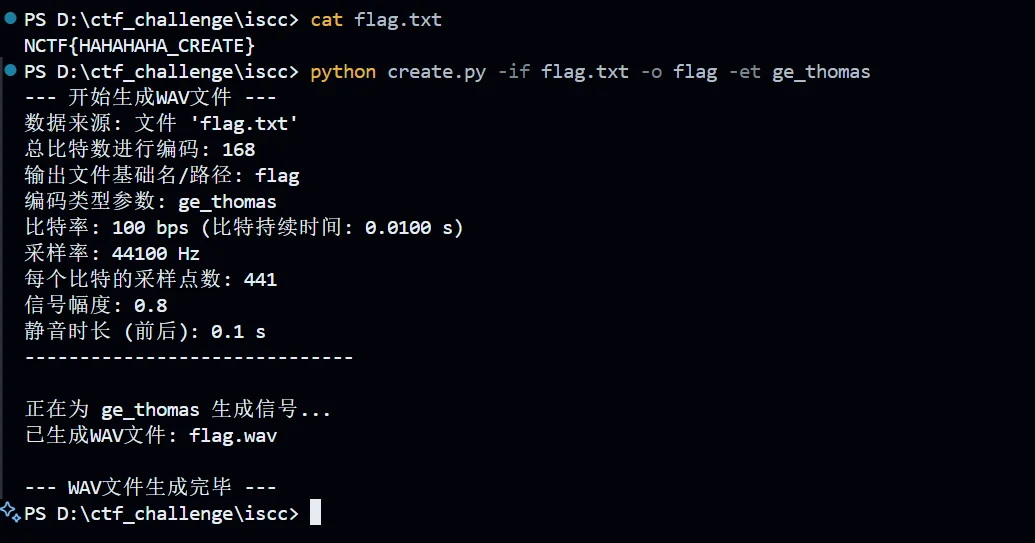
然后比对一下参数
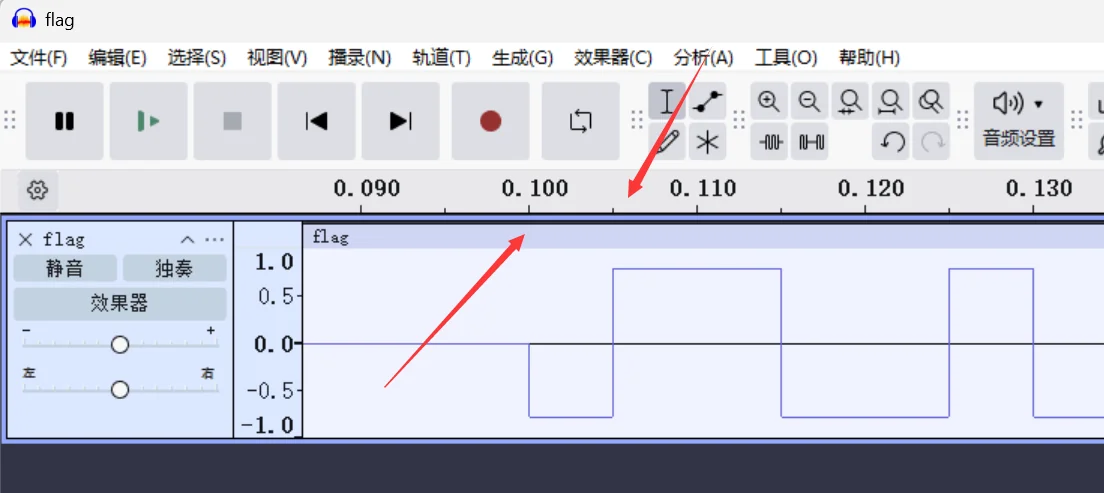
完全满足这里的比特率 100bps 和信号幅度 0.8 还有前后静音时长 0.1,然后我们尝试下提取数据信息
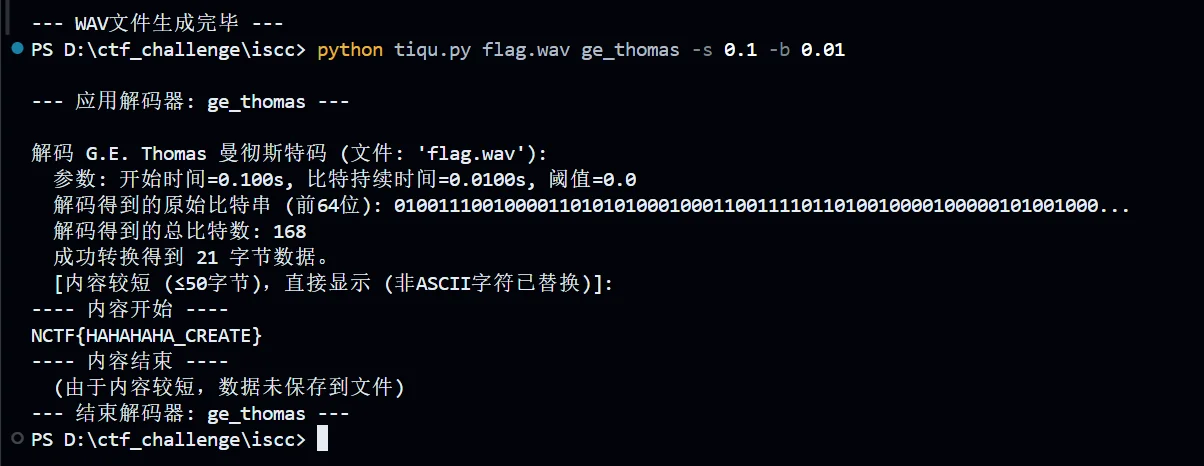
很 ok 喔
本代码的亮点是:灵活,特别灵活,可以将指定的二进制编码隐藏进去,也可以指定任意格式文件,将二进制数据编码进去,然后还能自定义编码类型,类型也很丰富的,还能自己调节其他参数的
说些什么吧!